缓存不一致的问题
使用缓存时会出现缓存中的数据和数据库中的数据不一致的情况。
使用缓存的两种模式
- 只读模式
当更新或删除数据时不更新缓存而是直接删除缓存
- 读写模式
当插入、更新或删除数据时同时更新缓存和数据库
只读模式下出现缓存不一致的情况:
情况一:缓存删除失败
更新/删除数据时
先删除缓存后更新数据库,如果缓存删除成功数据库更新失败,缓存会被重新创建此时没有影响。
先更新数据库,后删除缓存,如果缓存删除失败则会出现缓存不一致。
解决方案: 重试机制
可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中(例如使用 Kafka 消息队列)。当应用没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后再次进行删除或更新。
情况二: 并发请求
- 先删除缓存再更新数据库
| 时间 | 线程A | 线程B |
|---|---|---|
| t1 | 删除数据X缓存 | |
| t2 | 查询X缓存中未命中,从数据库中查询数据并更新缓存 | |
| t3 | 更新数据库 |
如上表所示,当出现并发操作时,最终会导致缓存中的数据依旧是旧值
- 先更新数据库再删除缓存
当数据库已经更新,缓存还未来得及删除时,其他请求仍然可能从缓存中读取到旧数据,但是时间很短对业务影响较小。
解决方案:
- 当采用先删除缓存再更新数据库时可以使用延迟双删来保证一致性,但延迟时间不好把握且不够优雅,伪代码:
1 | redis.delKey(X) |
- 使用分布式锁,将请求串行化
缓存雪崩
缓存雪崩是指大量的应用请求无法在 Redis 缓存中进行处理,紧接着,应用将大量请求发送到数据库层,导致数据库层的压力激增。
导致原因有:
- 缓存中大量数据同时过期,
- Redis服务不可用
避免方法:
- 这些数据的过期时间增加一个较小的随机数(例如,随机增加 1~3 分钟)
- 构建 Redis 缓存高可靠集群
缓存击穿
缓存击穿是指,针对某个访问非常频繁的热点数据的请求,无法在缓存中进行处理,紧接着,大量请求发送到了后端数据库,导致了数据库压力激增。缓存击穿的情况,经常发生在热点数据过期失效时,
解决方案:
- 热点数据不设置过期时间
- 使用互斥锁, 代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public String get(key) {
String value = redis.get(key);
if (value == null) { //代表缓存值过期
//设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可
sleep(50);
get(key); //重试
}
} else {
return value;
}
缓存穿透
缓存穿透是指要访问的数据既不在 Redis 缓存中,也不在数据库中,导致请求在访问缓存时,发生缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据。如果应用持续有大量请求,就会同时给缓存和数据库带来巨大压力。
一般来说,有两种情况:
- 业务层误操作:缓存中的数据和数据库中的数据被误删除了,所以缓存和数据库中都没有数据;
- 恶意攻击:专门访问数据库中没有的数据。
解决方案:
- 一旦发生缓存穿透,可以针对查询的数据,在 Redis 中缓存一个空值或是和业务层协商确定的缺省值(例如,库存的缺省值可以设为 0)
- 使用布隆过滤器快速判断数据是否存在
- 过滤不合法的请求
关于布隆过滤器
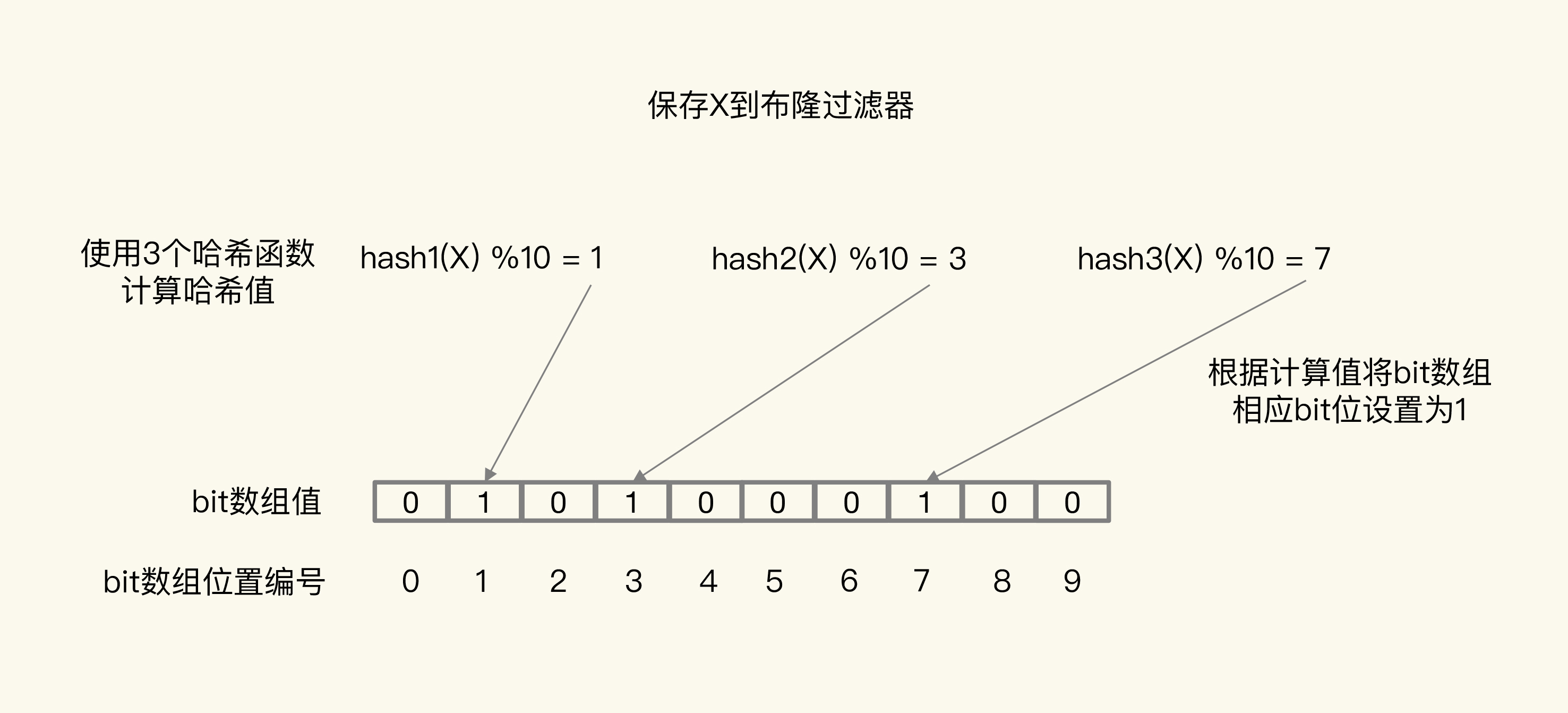
布隆过滤器由一个初值都为 0 的 bit 数组和 N 个哈希函数组成,可以用来快速判断某个数据是否存在。当我们想标记某个数据存在时(例如,数据已被写入数据库),布隆过滤器会通过三个操作完成标记:
- 首先,使用 N 个哈希函数,分别计算这个数据的哈希值,得到 N 个哈希值。
- 然后,我们把这 N 个哈希值对 bit 数组的长度取模,得到每个哈希值在数组中的对应位置。
- 最后,我们把对应位置的 bit 位设置为 1,这就完成了在布隆过滤器中标记数据的操作。
当需要查询某个数据时,我们就执行刚刚说的计算过程,先得到这个数据在 bit 数组中对应的 N 个位置。紧接着,我们查看 bit 数组中这 N 个位置上的 bit 值。只要这 N 个 bit 值有一个不为 1,这就表明布隆过滤器没有对该数据做过标记,所以,查询的数据一定没有在数据库中保存。
注意布隆过滤器会有误判,由于数组长度有限, 不同的值可能映射到同一组bit上。它可以确定数据一定不存在,但不能确定一个数据是否一定存在。